


很可惜 T 。T 您现在还不是作者身份,不能自主发稿哦~
如有投稿需求,请把文章发送到邮箱tougao@appcpx.com,一经录用会有专人和您联系
咨询如何成为春羽作者请联系:鸟哥笔记小羽毛(ngbjxym)
这是彭文华的第92篇原创

一直想写一篇大数据计算引擎的综述,但是这个话题有点大。今天试试看能不能一口气写完。没想到一口气从7点写到了凌晨2点
大数据计算的起点是Hadoop的MapReduce。之前虽然有一些分布式计算的工具,但是公认的大数据计算引擎的始祖仍然是MapReduce,虽然现在已经逐渐被同是批处理的Spark替代了。如同MapReduce一样,Storm开启了流式数据处理的先河,现在也被如日中天的SparkStreaming完全替代。而Spark和SparkStreaming的前面,正有一颗冉冉升起的闪耀巨星-Flink。
我当年在做某市交通委项目的时候,用的是Oracle。数据就是从各个收费站、路网上Socket过来的每辆车辆监测数据,一天数据量好几百万。这个数据量现在看好像没啥,但是放在2013年就蒙圈了,那时候还在用Oracle。作为单体数据库管理系统,Oracle其承载能力是有限的,基本上一个月的数据就能撑爆了。单表2000万性能就明显下降,软件层面优化无望,只能寄希望于更好的硬件--小型机。当时的业界基本就是这个状态。
这个时候,Hadoop携MapReduce横空出世!google实验室发明了MapReduce和Google File System,Apache基金会的人大受启发,成功孵化了Hadoop项目。
单体数据库能力有限,最后只能期望硬件(CPU、内存)越来越强,相当于是追求个人武力值的不断超越。而Hadoop生态的核心是化整为零,分而治之。Hadoop可以将一个巨大的数据集进行切分,然后分发给N个机器上进行存储,执行计算任务时,Hadoop将MapReduce任务扔到存有数据的N台服务器上,各自执行Map和Reduce过程,最后汇聚成为最终结果。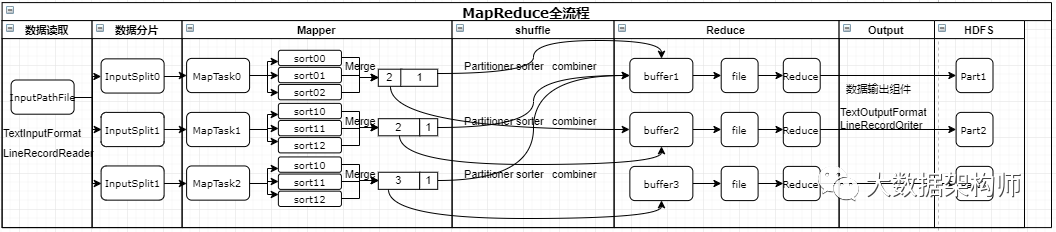
单台机器的进化有极限,而且成本会越来越高。而Hadoop的“分而治之”的思路完全打破了原有的单兵作战的套路,实施蜂群战术,让算力和服务器资源的线性增加成为可能。需要提升算力,只需要投入基本等同的普通计算机即可。
当时我们就用Hadoop的早期版本成功解决了交通项目数据海量线性增长的问题。对的,那时候还不叫“大数据”,叫“海量数据”。
MapReduce为了提升效率、增强鲁棒性,做了大量的精巧设计。比如为了解决Java的Full GC的问题,设计了环形缓冲区,以减少大量的内存申请和废弃操作;为了提升速度,在Map阶段做了大量的排序,Reduce阶段获取的数据天然有序,计算速度得到极大的提升。
MapReduce扩展阅读:
点击阅读:架构师带你细细的捋一遍MapReduce全流程【附调优指南】
虽然MapReduce是创始者,但是有各种问题备受数据工作者诟病。比如Hadoop源码是用Java开发的,抽数得写Java程序,数据工作者还得学Java;最令人忍受不了的是每次都要落地,一旦DAG较长,速度将变得无法忍受;还有就是基本都是T+1,不能实时出结果。
所以业界也在不断地研究如何提升效率。当时有两个主流发展方向:
提升速度;
追求实时。
Spark和Storm就是在这种状况下被发明出来的。加州伯克利大学AMP实验室选择的是提升计算速度的方向,他们想要发明一个比Hadoop快N倍的分布式计算引擎。他们做到了,这就是Spark!
MapReduce之所以慢,就是因为要保证集群的容错,因此所有操作结果都要落地一次,这个大量的磁盘刷写过程非常耗费时间。那么Spark的解决方案就出来了:所有操作都在内存里进行,没有了磁盘刷写,效率自然要高无数倍。
Spark把处理的数据集取个名字叫做“RDD”,即Resilient Distributed Datasets弹性分布式数据集。把计算逻辑抽象好,取个名字叫“算子”。整个计算过程就是输入-过滤算子-map算子-汇总算子-输出。
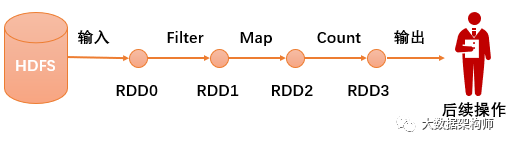
如上图所示,整个计算过程的所有数据全程不落地,减少了MapReduce无数次的磁盘刷写过程,效率自然百倍的提升!
但是这么做有一个风险:因为数据都在内存里,一旦某台机器挂掉,就会导致该节点所有流程数据全部废掉。所以Spark的Task有一个“推测执行”的机制,一旦发现你这个机器因为某些原因,没有在预定时间内反馈结果,则在集群内有同样数据的节点上再起一个相同的任务,同时跑,哪个先执行完,就用那个结果。而且RDD本身也能借助RDD的血缘关系lineage graph机制避免重新计算,一旦某个RDD计算时挂了,其他节点不用重新计算,继续接力跑就可以了。
至于Twitter开源的Storm,它有一个别称:实时的Hadoop。是的,Storm选择了另外发展方向:实时数据处理,它选择来一条数据处理一条数据。因此它的延迟非常小,但是可以想象,吞吐量肯定出问题。
而Storm对于数据消费的态度是不丢就好,一旦发现数据丢了,就重新再来一次。
但是!如果这个时候原来的数据没丢,只是网络延迟,那么这个数据就会重复计算。这个毛病直到现在都没有太好的方法解决,也是诸多使用者极为诟病的地方。
另外一个饱受诟病的地方是它的语言。Storm使用一种极为偏门的语言,用户体验非常不好,所以SparkStreaming一出,立刻就挤占了Storm的市场。
Spark扩展阅读:
Spark获得成功之后,AMP实验室并没有停下脚步,他们也开始选择另外一个方向进行突破:实时计算!
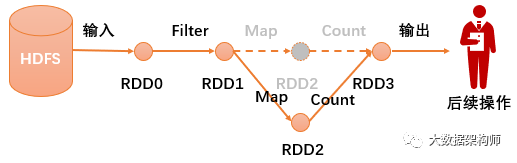
不得不说惯性思维很恐怖, 即便是AMP如此聪明的大脑们都饱受其影响。从SparkStreaming的设计理念上就能看出Spark的影子。虽然SparkStreaming被归类于流式数据处理引擎,但是严格来说,它其实是微-批处理。这个其实源自于各个开发团队对于数据颗粒度的认知,如同物理学上对光是粒子还是波的认知一样。
AMP认为流式数据其实是连续的,因此认定"流是批的特例"。那么流式数据的计算就是将连续不断的批量数据进行持续的批计算,如果把批量数据切分成足够小的DStream,那么就是实时了。
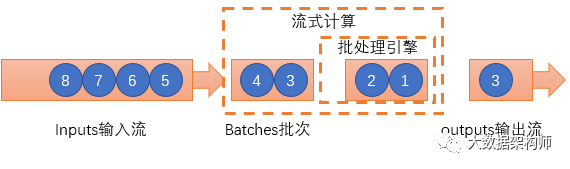
这个设计给SparkStreaming带来了非常优秀的特性:
比Storm更高的吞吐量,不是一条一条,而是几条几条的处理;
失败恢复超快,因为都是小批的数据计算,失败了干掉就好了;
与Spark几乎一样,数据工作者只需要搞定一套 ETL 逻辑就能同时搞定跑批和流式计算。
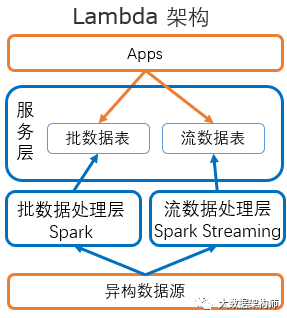
而Spark+SparkStreaming的组合,也成为了近几年的业界主流,这种批、流分开设计的架构被成为Lambda:
SparkStreaming扩展阅读:
点击阅读:SparkStreaming实时任务处理的三种语义
在所有人都认为Spark+SparkStreaming是大数据计算最佳实践的时候,Apache没有停止技术创新的脚步。虽然我没有深挖,但是我猜想,是两个流派对流式数据两个不同的认知,从而发展出两套流式计算的体系。
与AMP实验室的"流是批的特例"不一样,Apache基金会对于流式数据的认知正好反过来,他们认为"批是流的特例"。
如果AMP认为光是波,那么Apache基金会则认为光是粒子。两种认知,产生了同样优秀的两个不同的产品。
Apache基金会2016年发布Flink1.0版以来,受到了市场极大的关注。比如阿里在Flink基础上继续优化改造成了Blink。
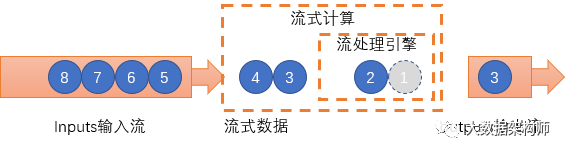
基于"批是流的特例"的认知,Flink类同于Strom,数据来一条处理一条,真正实现了流式数据处理。
这种处理模式与Storm一样,拥有极低的延迟,比SparkStreaming要高,但是比Spark要低。
Flink通过进程内部的各种优化,降低数据传输频次,提升传输速度,多个逻辑之间可以通过Chain机制,通过一个Task来处理多个算子。通过方法调用传参的形式进程数据传输,大大降低所需传输的数据。
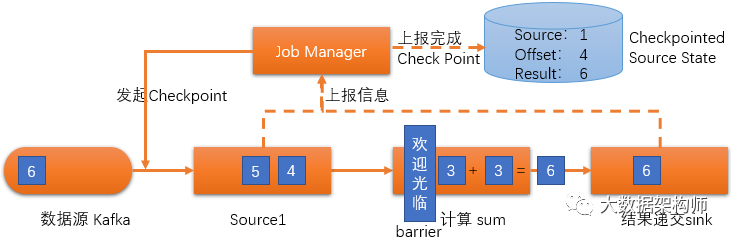
另外,Flink还创造了一种超级优雅的流式数据快照方式Checkpoint:
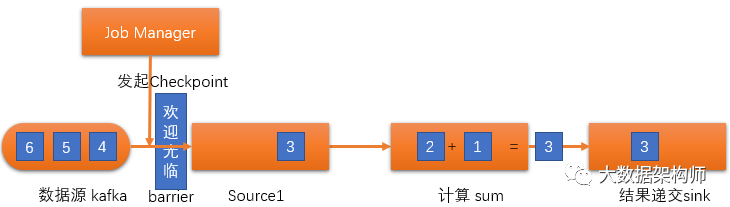
Checkpoint机制的实现原理是在需要设置快照的时候,由JobManager发起Checkpoint,在Source前放置一个Barrier标识。

就像超市隔断两个顾客采购商品的“欢迎光临”隔档一样,把快照前后的数据隔开。“欢迎光临”Barrier下游的数据,Flink会照常执行。当所有下游数据执行完毕之后,各部分会上报当前状态数据,递交至Checkpoint Source State保存起来。一旦节点出问题,重启任务,然后到Checkpoint Source State读取任务元数据即可继续进行。
另外,Flink和Spark不一样,对于乱序数据也提出了非常优雅的解决方案:Watermark。
Watermark就像是野外徒步小队中的后队领队一样,它决定了这个window的预期最后一个数据。这样能最大程度保证一个Flink Window的数据不会因为网络延迟等原因造成数据的丢失。
而且Flink还通过Checkpoint等一系列的设计,控制了Flink的数据严格消费一次(EXACTLY_ONCE)的计算原则,确保数据不丢、不重复。这也是优于Strom点之一。
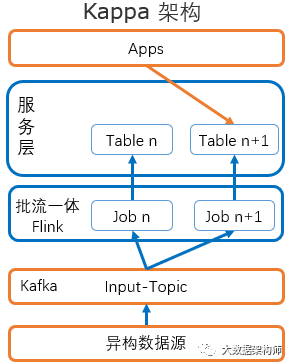
Flink严格来说,应该是流批一体,因为它的核心是流,同时能做批处理。这种架构被称为Kappa架构,与Spark+SparkStreaming的Lambda架构对应。
Spark Streaming 里的 DStream其实还是一个小的批,由定时器通知处理系统进行处理。这样的操作是用批的方式实现流式计算,但是会有不支持乱序、难以处理复杂流计算、背压等各种问题。另外,Spark Streaming不能很好的支持exactly-once 语义(可以,但是会变慢),只能较好的支持 at-least-once 语义。
而Flink以数据流为核心认知,将数据理解为最细颗粒度,从根本解决了流式数据计算的问题。它的各种窗口能灵活应对各种流、批数据处理需求,满足各种复杂的流式计算。
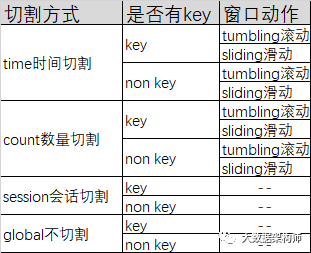
用Watermark解决乱序问题,用Checkpoint等各种设计达成exactly-once语义。一套工具,解决流、批数据处理的所有需求。这符合了广大数据工作者追求功能强大、一套通用、使用友好的完美计算引擎想象。关键是Flink还非常简单易用,所以Flink不火都天理难容啊!
Flink扩展阅读:
点击阅读:Flink如何巧用WaterMark机制解决乱序问题
Flink是终结者吗?我想不会的。纵观大数据计算引擎的发展历史,我们可以看到:
Hadoop的MapRedce开创了超大规模数据集合处理的先河,Strom开创了分布式流式数据计算引擎,可以为奉为大数据计算引擎鼻祖。
Spark充分利用内存,将超大规模数据集合处理速度提升了百倍;SparkStreaming则用微批理念处理流式数据,进一步解决Storm可能重复消费的弊病,同时降低延迟,提升效率,可以奉为第二代大数据计算引擎;
Flink创新性的引入Checkpoint机制、Watermark机制、各种灵活的窗口,同时满足流、批数据的超高吞吐、低延迟、灵活快速计算的各种需求,可以奉为第三代大数据计算引擎。
但是Flink仍然尚在不断发展,尚有更多有待优化和解决的点。无比期待Flink能越来越好。同样,我无比期望有更强的牛人,能创造出更加优秀的计算引擎!也希望朋友圈也能出现这样的牛人,我好顶礼膜拜
有人问,老彭,你这每天都这么写,怎么能坚持下来啊?其实这个问题就很有意思,这些朋友的潜台词是每天花4、5个小时一屁股坐下来写东西,还要画画,这样太痛苦了。其实不然!我在学习、整理资料的过程,其实就是在与那一个个聪明的大脑隔空神交,欣赏这些奇思妙想,用各种闻所未闻的脑洞来解决各种看似不可解的难题,这得多带劲啊?虽然我的老腰都快断了
另外,本文只是综述,不是选型依据。一个合格的架构师应该明白,最好的架构是最适合当前业务场景,且满足现有条件的,而不是最前沿的技术。
如果我没说清楚,可以在后台留言,我们一起学习,共同进步。感谢!
配合以下文章享受更佳
干货 | 一口气说穿中台-给你架构师的视角
全解 | 一口气说穿数据中台-给你架构师的视角
我需要你的点赞,爱你哟
本文为作者独立观点,不代表鸟哥笔记立场,未经允许不得转载。
《鸟哥笔记版权及免责申明》 如对文章、图片、字体等版权有疑问,请点击 反馈举报


















Powered by QINGMOB PTE. LTD. © 2010-2022 上海青墨信息科技有限公司 沪ICP备2021034055号-6






















我们致力于提供一个高质量内容的交流平台。为落实国家互联网信息办公室“依法管网、依法办网、依法上网”的要求,为完善跟帖评论自律管理,为了保护用户创造的内容、维护开放、真实、专业的平台氛围,我们团队将依据本公约中的条款对注册用户和发布在本平台的内容进行管理。平台鼓励用户创作、发布优质内容,同时也将采取必要措施管理违法、侵权或有其他不良影响的网络信息。
一、根据《网络信息内容生态治理规定》《中华人民共和国未成年人保护法》等法律法规,对以下违法、不良信息或存在危害的行为进行处理。
1. 违反法律法规的信息,主要表现为:
1)反对宪法所确定的基本原则;
2)危害国家安全,泄露国家秘密,颠覆国家政权,破坏国家统一,损害国家荣誉和利益;
3)侮辱、滥用英烈形象,歪曲、丑化、亵渎、否定英雄烈士事迹和精神,以侮辱、诽谤或者其他方式侵害英雄烈士的姓名、肖像、名誉、荣誉;
4)宣扬恐怖主义、极端主义或者煽动实施恐怖活动、极端主义活动;
5)煽动民族仇恨、民族歧视,破坏民族团结;
6)破坏国家宗教政策,宣扬邪教和封建迷信;
7)散布谣言,扰乱社会秩序,破坏社会稳定;
8)宣扬淫秽、色情、赌博、暴力、凶杀、恐怖或者教唆犯罪;
9)煽动非法集会、结社、游行、示威、聚众扰乱社会秩序;
10)侮辱或者诽谤他人,侵害他人名誉、隐私和其他合法权益;
11)通过网络以文字、图片、音视频等形式,对未成年人实施侮辱、诽谤、威胁或者恶意损害未成年人形象进行网络欺凌的;
12)危害未成年人身心健康的;
13)含有法律、行政法规禁止的其他内容;
2. 不友善:不尊重用户及其所贡献内容的信息或行为。主要表现为:
1)轻蔑:贬低、轻视他人及其劳动成果;
2)诽谤:捏造、散布虚假事实,损害他人名誉;
3)嘲讽:以比喻、夸张、侮辱性的手法对他人或其行为进行揭露或描述,以此来激怒他人;
4)挑衅:以不友好的方式激怒他人,意图使对方对自己的言论作出回应,蓄意制造事端;
5)羞辱:贬低他人的能力、行为、生理或身份特征,让对方难堪;
6)谩骂:以不文明的语言对他人进行负面评价;
7)歧视:煽动人群歧视、地域歧视等,针对他人的民族、种族、宗教、性取向、性别、年龄、地域、生理特征等身份或者归类的攻击;
8)威胁:许诺以不良的后果来迫使他人服从自己的意志;
3. 发布垃圾广告信息:以推广曝光为目的,发布影响用户体验、扰乱本网站秩序的内容,或进行相关行为。主要表现为:
1)多次发布包含售卖产品、提供服务、宣传推广内容的垃圾广告。包括但不限于以下几种形式:
2)单个帐号多次发布包含垃圾广告的内容;
3)多个广告帐号互相配合发布、传播包含垃圾广告的内容;
4)多次发布包含欺骗性外链的内容,如未注明的淘宝客链接、跳转网站等,诱骗用户点击链接
5)发布大量包含推广链接、产品、品牌等内容获取搜索引擎中的不正当曝光;
6)购买或出售帐号之间虚假地互动,发布干扰网站秩序的推广内容及相关交易。
7)发布包含欺骗性的恶意营销内容,如通过伪造经历、冒充他人等方式进行恶意营销;
8)使用特殊符号、图片等方式规避垃圾广告内容审核的广告内容。
4. 色情低俗信息,主要表现为:
1)包含自己或他人性经验的细节描述或露骨的感受描述;
2)涉及色情段子、两性笑话的低俗内容;
3)配图、头图中包含庸俗或挑逗性图片的内容;
4)带有性暗示、性挑逗等易使人产生性联想;
5)展现血腥、惊悚、残忍等致人身心不适;
6)炒作绯闻、丑闻、劣迹等;
7)宣扬低俗、庸俗、媚俗内容。
5. 不实信息,主要表现为:
1)可能存在事实性错误或者造谣等内容;
2)存在事实夸大、伪造虚假经历等误导他人的内容;
3)伪造身份、冒充他人,通过头像、用户名等个人信息暗示自己具有特定身份,或与特定机构或个人存在关联。
6. 传播封建迷信,主要表现为:
1)找人算命、测字、占卜、解梦、化解厄运、使用迷信方式治病;
2)求推荐算命看相大师;
3)针对具体风水等问题进行求助或咨询;
4)问自己或他人的八字、六爻、星盘、手相、面相、五行缺失,包括通过占卜方法问婚姻、前程、运势,东西宠物丢了能不能找回、取名改名等;
7. 文章标题党,主要表现为:
1)以各种夸张、猎奇、不合常理的表现手法等行为来诱导用户;
2)内容与标题之间存在严重不实或者原意扭曲;
3)使用夸张标题,内容与标题严重不符的。
8.「饭圈」乱象行为,主要表现为:
1)诱导未成年人应援集资、高额消费、投票打榜
2)粉丝互撕谩骂、拉踩引战、造谣攻击、人肉搜索、侵犯隐私
3)鼓动「饭圈」粉丝攀比炫富、奢靡享乐等行为
4)以号召粉丝、雇用网络水军、「养号」形式刷量控评等行为
5)通过「蹭热点」、制造话题等形式干扰舆论,影响传播秩序
9. 其他危害行为或内容,主要表现为:
1)可能引发未成年人模仿不安全行为和违反社会公德行为、诱导未成年人不良嗜好影响未成年人身心健康的;
2)不当评述自然灾害、重大事故等灾难的;
3)美化、粉饰侵略战争行为的;
4)法律、行政法规禁止,或可能对网络生态造成不良影响的其他内容。
二、违规处罚
本网站通过主动发现和接受用户举报两种方式收集违规行为信息。所有有意的降低内容质量、伤害平台氛围及欺凌未成年人或危害未成年人身心健康的行为都是不能容忍的。
当一个用户发布违规内容时,本网站将依据相关用户违规情节严重程度,对帐号进行禁言 1 天、7 天、15 天直至永久禁言或封停账号的处罚。当涉及欺凌未成年人、危害未成年人身心健康、通过作弊手段注册、使用帐号,或者滥用多个帐号发布违规内容时,本网站将加重处罚。
三、申诉
随着平台管理经验的不断丰富,本网站出于维护本网站氛围和秩序的目的,将不断完善本公约。
如果本网站用户对本网站基于本公约规定做出的处理有异议,可以通过「建议反馈」功能向本网站进行反馈。
(规则的最终解释权归属本网站所有)